
Your basket is currently empty!
Category: AI info
Perplexity AI Evaluation Report
Perplexity AI Evaluation Report A comprehensive assessment of accuracy, source citation, search integration, and real-time research capabilities 1. Accuracy & Factual Reliability Perplexity excels in delivering factually grounded responses with minimal hallucination, leveraging real-time search and strict citation standards. Metric Score (out of 10) Description Factual Accuracy 9.5 Consistently verifies claims via live sources Hallucination…
DeepSeek AI Model Evaluation Report
DeepSeek AI Model Evaluation Report A comprehensive assessment of DeepSeek’s large language models in reasoning, coding, multilingual support, and real-world performance 1. Reasoning & General Intelligence DeepSeek models demonstrate strong logical reasoning and factual knowledge, rivaling top-tier Western LLMs in both Chinese and English benchmarks. Benchmark Score Model Version MMLU (5-shot) 82.6 DeepSeek-V2 CEval (Chinese)…
Midjourney AI Image Generation Evaluation Report
Midjourney AI Image Generation Evaluation Report A comprehensive assessment of visual quality, prompt understanding, style diversity, and creative usability 1. Image Quality & Visual Fidelity Midjourney produces some of the most artistically compelling and visually rich images among all text-to-image models, especially in fantasy, concept art, and stylized photography. Category Score (out of 10) Description…
GitHub Copilot Multi-Dimensional Evaluation Report
GitHub Copilot Multi-Dimensional Evaluation Report A comprehensive assessment of AI-powered coding assistance, language support, accuracy, and developer productivity 1. Code Generation & Functional Accuracy Copilot excels at generating syntactically correct and context-aware code across multiple programming languages, significantly reducing boilerplate and accelerating development. Language Accuracy Rate Use Case Example Python 92% Generate data processing scripts…
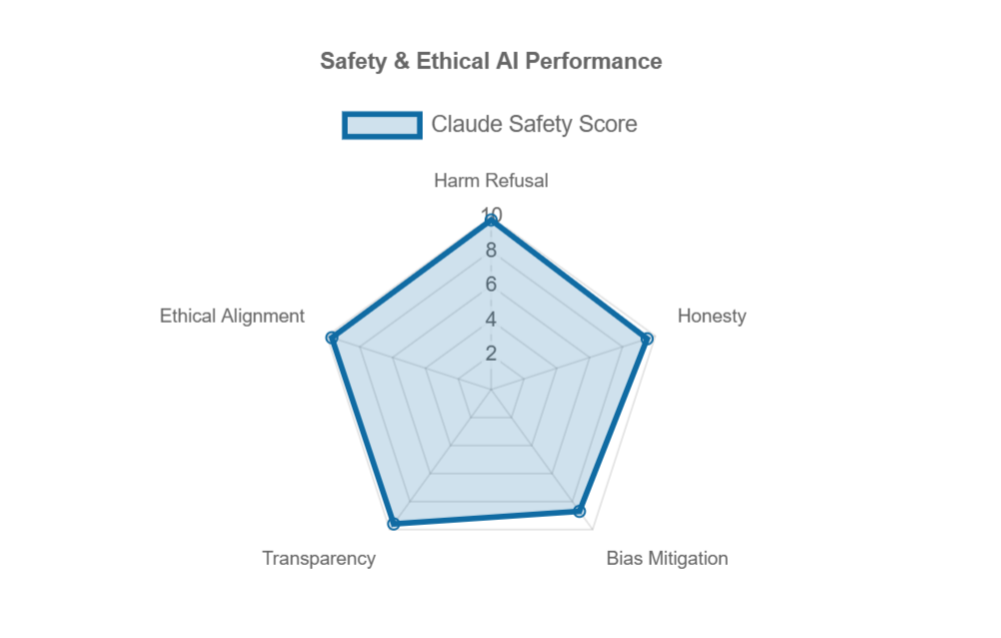
Claude AI Multi-Dimensional Review|Detailed Benchmark Across Key AI Capabilities
Anthropic Claude Multi-Dimensional Evaluation Report A comprehensive assessment of reasoning, safety, long-context capabilities, and real-world usability 1. Reasoning & Logical Intelligence Claude excels in deep reasoning, structured thinking, and complex problem-solving, making it ideal for technical, legal, and analytical tasks. Skill Performance Score Use Case Example Logical Deduction 9.6 / 10 Identify flaws in arguments…
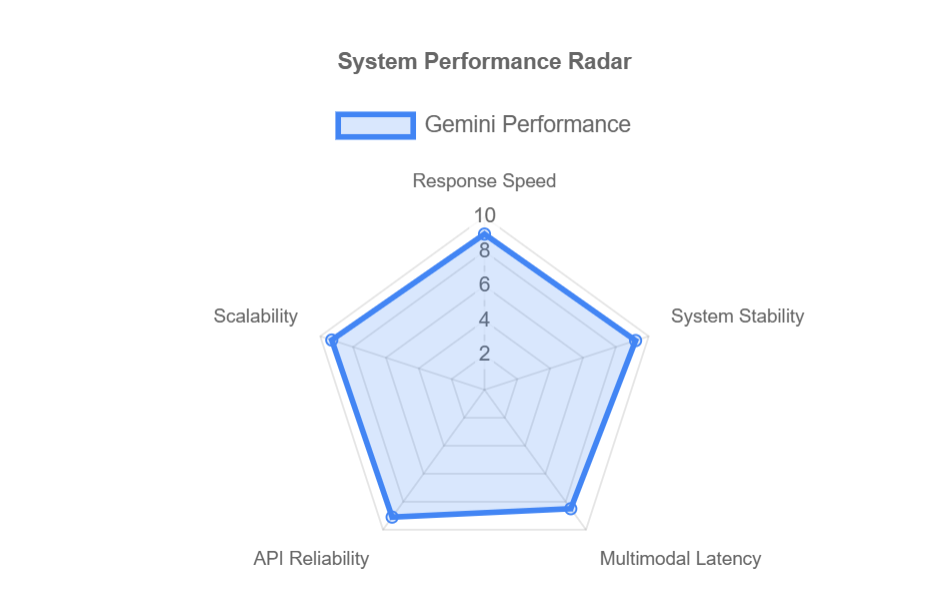
Google Gemini Benchmark Report|Language, Search, Safety & User Experience
Google Gemini Multi-Dimensional Evaluation Report A comprehensive assessment of multimodal AI, search integration, safety, and real-world usability 1. Multimodal Understanding Gemini excels in processing text, images, audio, and code together, leveraging Google’s deep multimodal research and ecosystem. Modality Integration Quality Use Case Example Text + Image 9.2 / 10 Analyze screenshots, diagrams, and photos with…
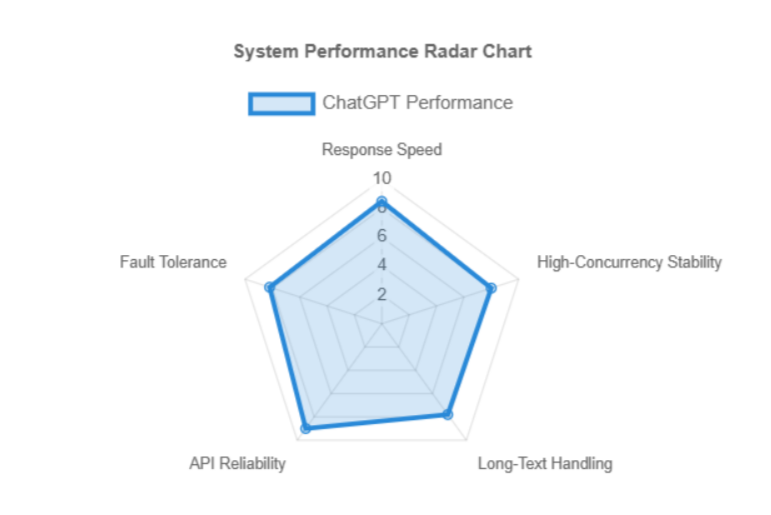
2025 ChatGPT Benchmark Report|Accuracy, Speed, Creativity & More
ChatGPT Multi-Dimensional Evaluation Report A comprehensive assessment across accuracy, response speed, language capability, and more 1. Language Understanding & Generation ChatGPT excels in natural language understanding (NLU) and generation (NLG), handling complex syntax, contextual reasoning, and multi-turn conversations effectively. Metric Score (out of 10) Description Grammatical Accuracy 9.5 Rare grammatical errors; expressions are natural and…